Sinds januari 2017 werk ik vanuit Craftsmen bij een van de grotere telecombedrijven van Nederland. Mijn team heeft hier onder meer de missie om de nieuwe mobiele app en website sneller en stabieler te maken.
Een manier waarop we dit doen is het neerzetten van een volledig nieuwe microservices-omgeving, binnen Docker (Swarm) op basis van Spring Boot.
Alles is nieuw, dus kunnen we het inrichten zoals we willen: om te zorgen dat het snel en stabiel is. Wat makkelijker gezegd dan gedaan is, want we hebben natuurlijk te maken met het bestaande landschap en de legacy-systemen.
En zoals we allemaal weten staan legacy-systemen meestal niet bekend om hun snelheid. Hier geldt niks anders.
Bovendien komt het erop neer dat de gegevens in deze oude systemen leidend zijn en dit daarom onze bronsystemen zijn…
De systemen waar het om gaat zijn standaardpakketten die door externe partijen in verre landen worden gecustomized voor deze telecomprovider.
Nu heb ik in het verleden vaak genoeg met performanceproblemen in standaardpakketten te maken gehad, met de nodige uitdagingen. Om er een paar, vast herkenbare, te noemen:
- Je moet bij iedere aanpassing in de standaardfunctionaliteit rekening houden met toekomstige updates; bij iedere update moet je controleren of je aanpassingen nog steeds doen wat ze moeten doen, en of ze niet nieuwe dingen kapotmaken.
- Vaak verlies je door de aanpassingen een deel van de standaardfunctionaliteit. Dat hoeft niet erg te zijn op dat moment, maar op een dag kan iemand zich opeens bedenken dat dat deel van de standaardfunctionaliteit, een deel dat we vanwege performance-issues geloosd hebben, nu opeens vereist is.
- En uiteindelijk vervaagt ook de grens tussen je eigen customcode en de standaardcode van het pakket. In het geval van troubles hebben de leveranciers dan meestal een eenvoudige oplossing: je support is vervallen.
Aanpassen is dus niet altijd de beste route. Ook bij deze klant is daarom gekozen om de oplossing elders te zoeken.
Een interessant probleem, want uitgerekend *de bron* van onze gegevens is niet snel en wij moeten zorgen dat het geheel snel wordt.
Makkelijker gecachet, dan gedaan…
De eerste oplossing die we hebben geïmplementeerd is caching. Aangezien we met Spring Boot werken, is caching op methods via de @Cacheable annotation snel en eenvoudig inzetbaar.
We gebruiken Hazelcast, wat een over het netwerk gedistribueerde cache heeft, zodat alle instances van dezelfde service de cache delen.
Het toevoegen van caching levert een aanzienlijke versnelling op. We kunnen nu, vanwege de cache, in een aantal milliseconden een response gegeven. De versnelling is vaak een factor 10 of meer.
Helaas geldt deze snelheidswinst logischerwijs pas bij de tweede request van dezelfde gegevens. Het eerste request blijft traag voor de klant.
Na wat brainstormen hebben we een verdiepingsslag bedacht. De gegevens die we cachen zijn specifiek voor de klant: de klant moet altijd inloggen, voordat hij toegang krijgt tot de gecachete informatie.
Waarom laten we dan niet bij het inloggen alvast de cache vullen?
Juist. Precies wat we hebben gedaan.
We hebben een nieuwe service gemaakt die direct na de login wordt aangeroepen. Deze service doet niets anders dan asynchroon aan de sessie van de gebruiker andere services aanroepen, om alvast de cache te vullen met de gegevens voor de vers ingelogde klant.
Aangezien deze service de response van de andere services niet nodig heeft, hebben we in deze andere services een nieuw endpoint toegevoegd dat geen response maakt en alleen de cache vult.
Sinds deze aanpassing is de performance echt merkbaar verbeterd.
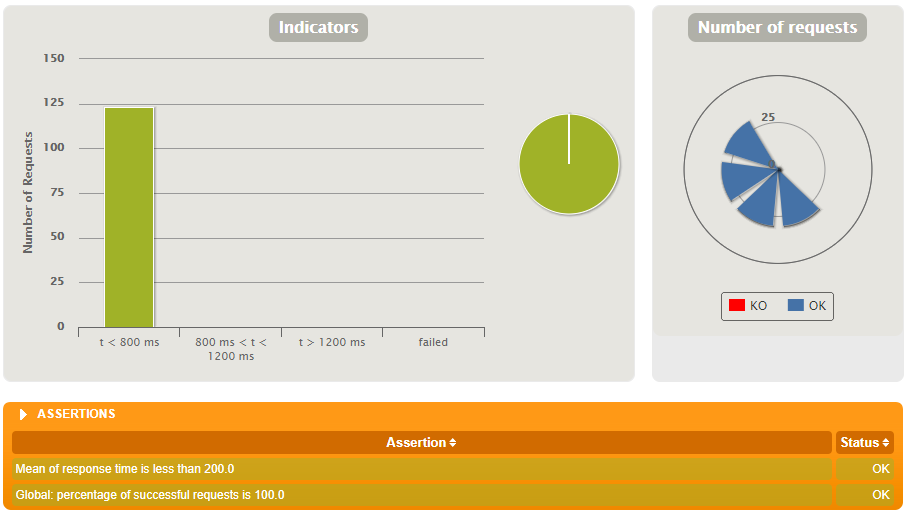
Nu dit allemaal werkt, hebben we nog maar één probleem: de bronbestanden die wij cachen kunnen uiteraard door anderen op bronniveau aangepast worden. En als dat gebeurt, dan geeft onze gecachete service soms verkeerde informatie terug.
Een mooi voorbeeld hiervan is de service die de factuurinformatie ophaalt. In de praktijk komt het best vaak voor dat een klant inlogt, naar zijn factuurinformatie kijkt, ziet dat er een factuur nog betaald moet worden en besluit de betaling te gaan doen.
Deze betaling doet hij via een andere microservice, dus onze factuurservice houdt vrolijk de informatie over de onbetaalde factuur in zijn cache.
Gevolg is dat als de klant nadat hij heeft betaald nog even controleert of hij echt heeft betaald, dat hij dan – onterecht – ziet dat hij nog steeds een openstaande factuur heeft.
Enter RabbitMQ
De oplossing die wij hiervoor hebben bedacht is om via RabbitMQ, wat heel goed integreert in Spring Boot met de @RabbitListener annotation, berichten uit te wisselen. Na de bevestiging van de betaling stuurt de iDEAL-service een MQ-bericht aan de factuurservice met het betaalde bedrag en het nummer van de invoice.
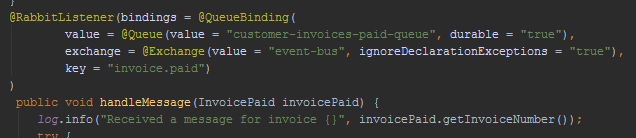
Hierna is het aan ons om te zorgen voor een cache-update.
Helaas verwerken de legacy-systemen de betaling niet direct, dus simpelweg de factuurinformatie uit de cache verwijderen en opnieuw van de bron ophalen, is niet de oplossing. Daarom passen we de informatie alvast aan alsof de betaling (ook in de bronsystemen) al verwerkt is.
De zojuist betaalde factuur krijgt nu dus de status “betaald”.
Deze informatie stoppen we weer in de cache en als de gebruiker nu controleert of hij al heeft betaald, dan ziet hij dat dat inderdaad zo is.
Tegen de tijd dat de informatie in de cache is verlopen, heeft onze backend de betaling ook verwerkt en is alles weer in sync.
But wait (of liever niet dus), there’s more
Andere technieken die we nog gebruiken ter bevordering van de snelheid zijn het asynchroon aan de sessie van de gebruiker uitvoeren van bepaalde processen.
Dit is iets wat niet vaak kan, maar wel bij bijvoorbeeld logging van events voor een callcenter. Zodat de callcentermedewerkers in het CRM-pakket zien wat de gebruiker heeft gedaan.
Het is in dit laatste geval niet heel erg als iets misgaat, maar als we hier ook gebruikmaken van queuing is het betrouwbaar genoeg te maken.
Ook hebben we nog een paar services geoptimaliseerd die uit meerdere backend-systemen informatie halen, met parallelle requests.
Tot zover wat we tot nu toe hebben gedaan om ervoor te zorgen dat aplicatiegebruikers geen last hebben van de traagheid van de legacy-systemen.
We zijn er bijna
Ik denk niet dat we al klaar zijn, want ik zie nog genoeg mogelijkheden om bijvoorbeeld meer gebruik te maken van queueing om hiermee ook bij POST- en PUT-operaties te zorgen dat de belevingssnelheid toeneemt.
Ook kunnen bij sommige services meer delen parallel of asynchroon aan de gebruikerrequests worden uitgevoerd.
Wie weet hierover later (of sneller) meer 🙂




