Introduction
Recently I had to process a large file containing records in a Cobol (copybook) format and load the data into a new system. My choice of framework for this was Spring Batch, because Spring Batch offers some good functionality to read and process large files with fixed line length. In this blog I am going to explain how I did this.
The use case
The use case was to read a large file from an old z/OS system and process the records so they can be stored into a new microservice landscape. I created two microservices for this:
1. A Spring Batch application which reads (parses) the file, processes the records and sends them to another Spring Boot microservice responsible for that particular data.
2. A Spring Boot microservice responsible for maintaining the data in question.
I have created two sample applications which handle contact information:
1. The Spring Batch application reads (parses) a file with contact information, processes the records and sends them to the contacts service. See my spring-batch-demo service on Github.
2. The Spring Boot microservice stores the data and it can be used for retrieving the data. See my contacts service on Github.
In this blog I will only focus on the Spring Batch service.
The process (context)
The following figure shows the process interaction between both services. The contactsprocessor reads the file and processes record for record. Each record is posted as a json (Contact model) to the contacts service by using the contacts resource.
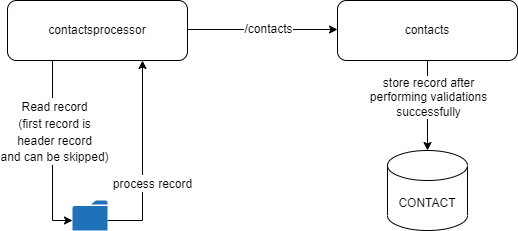
The flow diagram below describes the Spring Batch flow:

Processing with Spring Batch – The Maven dependencies
First we need to setup a Maven project with the necessary dependencies. In the example project I use spring-boot-starter-webflux since I am using WebClient instead of RestTemplate to call the contacts service. WebClient has a more functional approach and is fully reactive (although one could question whether reactive and Spring Batch go together, that is another discussion).
Another reason for using WebClient is that since Spring 5.0 RestTemplate has become deprecated and will not be getting any major updates. Spring advices not to use RestTemplate any more in new code.
I use Spring Boot 2.6.7 and I have included the spring-boot-dependencies as a bom in dependencyManagement so the other (Spring) dependencies can easily be referenced. To use Spring Batch we at least need to include spring-boot-starter-batch, which will provide the Spring Batch core dependencies.
Furthermore I am making use of the AsyncItemProcessor and AsyncItemWriter (more on this later) for which we need the spring-batch-integration dependency. Also see Spring Batch Integration.
By default Spring Batch uses a database to store metadata on configured batch jobs. This keeps track of which jobs have finished or which files have been processed for example. This can be overruled by implementing an in-memory Map based repository. For more on this see Spring Batch Example on CodeNotFound. The metadata tables are normally used for recovery and restart. Depending on your use case or functionality this is something you might or might not need. In the example project I am using Postgresql for storing the metadata tables for which we need the postgresql dependency.
For (integration)testing purposes we need the spring-boot-starter-test and spring-batch-test dependencies.
Below is a minimal setup you need for Spring Batch. Of course the project depends on more dependencies and plugins that are not Spring Batch specific. Please find the complete Maven pom in the project’s git repository.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>nl.craftsmen</groupId>
<artifactId>contactsprocessor</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>contactsprocessor spring-batch-demo</name>
<description>contactsprocessor</description>
<properties>
<!-- Java version and jdk properties -->
<java.version>11</java.version>
<version.java.compiler>${java.version}</version.java.compiler>
<version.java.source>${java.version}</version.java.source>
<version.java.target>${java.version}</version.java.target>
<!-- Spring versions -->
<spring-boot.version>2.6.7</spring-boot.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring Boot -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-integration</artifactId>
</dependency>
<!-- Other dependencies -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Necessary for Spring Batch if you want to schedule a batch job -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
</dependency>
<!-- Test: Spring -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<finalName>contactsprocessor</finalName>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${version.maven-compiler-plugin}</version>
<configuration>
<source>${version.java.source}</source>
<target>${version.java.target}</target>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
Spring Batch Terminology
A batch process usually consists of tasks (called jobs) and each job describes a processing flow (one or more steps). A step consists of three components:
ItemReader: reads (and parses) data from some input (database, queue, file, etc.).ItemProcessor: processes the data that is passed on from the item reader.ItemWriter: writes the data to some output (database, queue, file, etc.).
In Spring Batch there are two approaches of defining steps: using the chunk model or using the tasklet model. When using the latter, the reading, processing and writing steps are executed one after the other and it processes all data in a single run of these steps.
When dealing with large datasets, this may not be ideal, since you may run into problems with resources. Usually in batch processing you are dealing with a large set of data, so the chunk approach is the more ideal situation. By configuring a chunk size, the data can be processed in parts, thus limiting the amount of data being kept in memory significantly.
As mentioned earlier, by default Spring Batch uses a database to store metadata about jobs and step details. We can use the JobRepository to access this metadata and assign a datasource to it.
Spring Batch offers a JobLauncher which offers us the possibility to run a job, synchronously or asynchronously, either manually or scheduled. In order to run a job, a JobInstance needs to be created and JobParameters can be provided to this instance.
For more details also see Let’s Learn Together Sessions: Spring Batch.
Application walkthrough
In this section I will walk through the code that I setup for processing a file with fixed line lengths using Spring Batch. The complete source code is also available on Github.
The Springboot application
We create the following Spring Boot starter class with its main method. Key point here is that we add the @EnableBatchProcessing annotation to enable the Spring Batch functionality.
package nl.craftsmen;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication(scanBasePackages = { ContactProcessingApplication.ROOT })
@EnableBatchProcessing
public class ContactProcessingApplication {
public static final String ROOT = "nl.craftsmen";
public static void main(String[] args) {
SpringApplication.run(ContactProcessingApplication.class, args);
}
}
The job runner
Then we create a job runner class with a method that can either be scheduled or manually triggered. The job runner class consists of a JobLauncher , JobParameters , and the actual Job configuration. By adding the @Async annotation to the runProcessingContactsBatchJob method we indicate the job will run asynchronously and when completed it will return the id of the batch job. In this case the job is not scheduled.
package nl.craftsmen.contact.job;
import java.util.Objects;
import java.util.concurrent.CompletableFuture;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import nl.craftsmen.contact.job.config.ContactsJobParametersConfig;
import nl.craftsmen.exceptionhandling.BatchjobException;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersInvalidException;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Component;
@Component
@AllArgsConstructor
@Slf4j
public class ContactsJobRunner {
private static final String FILE_NAME_CONTEXT_KEY = "filename";
private final JobLauncher simpleJobLauncher;
private final ContactsJobParametersConfig contactsJobParametersConfig;
private final Job processingContactsJob;
@Async
public CompletableFuture<Long> runProcessingContactsBatchJob() {
return CompletableFuture.completedFuture(
Objects.requireNonNull(runJob(processingContactsJob,
contactsJobParametersConfig.getJobParameters()))
.getJobId());
}
private JobExecution runJob(Job job, JobParameters parameters) {
try {
return simpleJobLauncher.run(job, parameters);
} catch (JobExecutionAlreadyRunningException e) {
throw new BatchjobException(String.format("Job with filename=%s already running.",
parameters.getParameters().get(FILE_NAME_CONTEXT_KEY)), e);
} catch (JobRestartException e) {
throw new BatchjobException(String.format("Job with filename=%s was not started.",
parameters.getParameters().get(FILE_NAME_CONTEXT_KEY)), e);
} catch (JobInstanceAlreadyCompleteException e) {
throw new BatchjobException(String.format("Job with filename=%s was already
completed.",
parameters.getParameters().get(FILE_NAME_CONTEXT_KEY)), e);
} catch (JobParametersInvalidException e) {
throw new BatchjobException("Invalid job parameters.", e);
}
}
}
The job controller resource
For demo (and testing) purposes I have chosen to create a REST resource so the batch job can be triggered manually by using a GET request. This can also be useful when using some scheduling outside of the application, for example when using some orchestration pattern. The controller has two endpoints:
- /batchjob/run: to trigger the batch job.
- /batchjob/
removejobexecutions: to empty the Spring Batch metadata tables. This is not something you would use in a production environment, but it can be useful for end-to-end testing to start with an empty database. For example: we cannot process the same filename twice, so we want to delete the metadata content for testing with the same file.
The ContactsJobRepositoryCleanService consists of a DataSource and SpringJdbcScriptUtils which allows us to run an sql script (schema-delete-spring-batch-metadata.sql) containing delete statements on all the Spring Batch metadata tables.
package nl.craftsmen.contact;
import java.sql.SQLException;
import java.util.concurrent.ExecutionException;
import nl.craftsmen.contact.job.ContactsJobRunner;
import nl.craftsmen.contact.model.Batchjob;
import org.springframework.batch.core.JobParametersInvalidException;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
@RestController
@RequestMapping(ContactsBatchJobController.RESOURCE)
@AllArgsConstructor
@Slf4j
public class ContactsBatchJobController {
static final String RESOURCE = "/batchjob";
private final ContactsJobRunner contactsJobRunner;
private final ContactsJobRepositoryCleanService contactsJobRepositoryCleanService;
@GetMapping("/run")
public Batchjob run() throws ExecutionException, InterruptedException, JobInstanceAlreadyCompleteException,
JobExecutionAlreadyRunningException, JobParametersInvalidException, JobRestartException {
log.info(">>>>> Resource /batchjob/run called");
final var batchjobId = contactsJobRunner.runProcessingContactsBatchJob().get();
return Batchjob.builder().batchjobId(batchjobId).build();
}
@GetMapping("/removejobexecutions")
public String removeJobExecutions() throws SQLException {
log.info(">>>>> Resource /batchjob/removejobexecutions called");
contactsJobRepositoryCleanService.removeJobExecutions();
return "OK";
}
}
The job parameters
As mentioned in the ContactsJobRunner we provide it with some job parameters. This is a simple Spring configuration class with a bean getJobParameters , which returns a JobParameters object. The job parameters consists of a date and in this case a hardcoded filename of the file we want to process (in this case it is bundled within the application – see contacts.txt in /src/main/resources.
Normally this would be a file you read from somewhere else or that you receive on a queue for example.
package nl.craftsmen.contact.job.config;
import java.util.Date;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ContactsJobParametersConfig {
private static final String DATE_CONTEXT_KEY = "date";
private static final String FILE_NAME_CONTEXT_KEY = "filename";
/**
* For demo purposes this is now a static file from src/main/resources.
*/
private static final String FILE_TO_PROCESS = "contacts.txt";
@Bean
public JobParameters getJobParameters() {
final var jobParametersBuilder = new JobParametersBuilder();
jobParametersBuilder.addString(FILE_NAME_CONTEXT_KEY, FILE_TO_PROCESS);
jobParametersBuilder.addDate(DATE_CONTEXT_KEY, new Date());
return jobParametersBuilder.toJobParameters();
}
}
The job configuration
This is where you actually define the job configuration and the steps to be executed. Again, this is a Spring configuration class with a bean processingContact (returning a Job) which matches with the job defined in ContactsJobRunner. This is the actual job being triggered.
In this example the job “processingContacts” only contains one step named “readAndProcessContacts” which reads a file line by line, parses it into a model and processes (posts) each record to another service. I use the chunk based approach here which requires a reader, processor and writer component.
By default the chunksize is 1, but it is configurable in the application.yml file by setting the processingcontactsjob.chunksize property.
When defining the chunk we need to provide an input and an output. The input is a ContactWrapper (more on that later) and the output is a Future of a ContactWrapper. This is because we are using Spring Batch Integration’s AsyncItemProcessor and AsyncItemWriter which can be configured to increase Spring Batch performance. For more details on this see Increase Spring Batch Performance through Async Processing.
When an error occurs in a step the default behavior is that the step will fail. When configuring a job step we can also choose to add some skip logic. For example, we can choose to skip the first two errors by setting skipLimit(2) for skip(Exception.class) which will skip the first 2 exceptions that occur. Whatever that exception is. As such we can also skip specific exceptions like skip(NoResourceFoundException.class) or use noSkip(SAXException.class) if we never want to skip a SAXException.
To enable skip functionality we need to include a call to faultTolerant(0) during the step-building process in our step configuration before we add any skip steps. More on skip logic can be found in Configuring Skip Logic in Spring.
package nl.craftsmen.contact.job;
import java.util.concurrent.Future;
import lombok.AllArgsConstructor;
import nl.craftsmen.contact.job.faulthandling.ItemSkipPolicy;
import nl.craftsmen.contact.job.faulthandling.StepSkipListener;
import nl.craftsmen.contact.job.processor.AsyncContactsProcessorConfig;
import nl.craftsmen.contact.job.writer.AsyncContactsWriterConfig;
import nl.craftsmen.contact.model.ContactWrapper;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@AllArgsConstructor
public class ProcessContacts {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final ItemStreamReader<ContactWrapper> contactsReader;
private final int chunkSize;
private final ItemSkipPolicy itemSkipPolicy;
private final AsyncContactsProcessorConfig asyncContactsProcessorConfig;
private final AsyncContactsWriterConfig asyncContactsWriterConfig;
private final StepSkipListener stepSkipListener;
@Qualifier(value = "processContacts")
@Bean
public Job processingContactsJob() {
return jobBuilderFactory.get("processingContacts")
.start(readAndProcessContacts())
.build();
}
private Step readAndProcessContacts() {
return stepBuilderFactory.get("readAndProcessContacts")
.<ContactWrapper, Future<ContactWrapper>>chunk(chunkSize)
.reader(contactsReader)
.processor(asyncContactsProcessorConfig.getAsyncProcessor())
.writer(asyncContactsWriterConfig.getAsyncItemWriter())
.faultTolerant()
.skipPolicy(itemSkipPolicy) // unlimited skip
.skip(Exception.class) // ignore all Exceptions, so that next record will be processed
.listener(stepSkipListener)
.build();
}
}
For my use case I needed to skip all errors without any limit. To achieve this I implemented a custom skipPolicy which skips for any exception:
package nl.craftsmen.contact.job.faulthandling;
import lombok.NonNull;
import org.springframework.batch.core.step.skip.SkipLimitExceededException;
import org.springframework.batch.core.step.skip.SkipPolicy;
import org.springframework.stereotype.Component;
@Component
public class ItemSkipPolicy implements SkipPolicy {
@Override
public boolean shouldSkip(final @NonNull Throwable throwable, final int skipCount) throws SkipLimitExceededException {
return true;
}
}
But in case an exception does occur I want to log it, including the original line that was read. For this we can use Spring Batch Event Listeners, and in this particular case a SkipListener where we can implement some logic in case the step failed in the read, process or write part. Besides logging we can also choose to write the line that failed to be processed to a database.
When an error occurs in the reading part of the step this can result in a FlatFileParseException. In this case we can get hold of the line that was read and log it along with the exception. In any other case we can only log the exception.
When an error occurs in the process or write step, we also want to be able to log the line that was read. However, in the read process a mapping to the Contact model takes place and we lose the original line which was read. This is where the ContactWrapper comes in.
When mapping the line to a Contact model in the read process we also map the original input line that was read and we put both the Contact model and the original input in a ContactWrapper model. So we can always get a hold of the original line that was read in the onSkipInProcess and onSkipInWrite methods within the StepSkipListener.
package nl.craftsmen.contact.job.faulthandling;
import lombok.AllArgsConstructor;
import lombok.NonNull;
import lombok.extern.slf4j.Slf4j;
import nl.craftsmen.contact.model.ContactWrapper;
import nl.craftsmen.util.ConditionalLogger;
import org.springframework.batch.core.annotation.OnSkipInProcess;
import org.springframework.batch.core.annotation.OnSkipInRead;
import org.springframework.batch.core.annotation.OnSkipInWrite;
import org.springframework.batch.item.file.FlatFileParseException;
import org.springframework.stereotype.Component;
@Component
@AllArgsConstructor
@Slf4j
public class StepSkipListener {
private final ConditionalLogger logger;
@OnSkipInRead
public void onSkipInRead(@NonNull Throwable throwable) {
logReadError(throwable);
}
@OnSkipInProcess
public void onSkipInProcess(@NonNull ContactWrapper contactWrapper, @NonNull Throwable throwable) {
logProcessError(contactWrapper.getContactRecord(), throwable);
}
@OnSkipInWrite
public void onSkipInWrite(@NonNull ContactWrapper contactWrapper, @NonNull Throwable throwable) {
logWriteError(contactWrapper.getContactRecord(), throwable);
}
private void logReadError(Throwable throwable) {
if (throwable instanceof FlatFileParseException) {
final var exception = (FlatFileParseException) throwable;
logger.error(log, "Error occurred while reading an item: {}", exception.getInput(), throwable);
} else {
logger.error(log, "Error occurred while reading an item!", throwable);
}
}
private void logProcessError(String contact, Throwable throwable) {
logger.error(log, "Error occurred while processing item {}", contact, throwable);
}
private void logWriteError(String contact, Throwable throwable) {
logger.error(log, "Error occurred while writing an item: {}", contact, throwable);
}
}
Reading and parsing the file
The reader is responsible for reading the file with fixed length lines and parse each line to a Contact model which can be posted to the contacts service by the processor component. The ProcessContactsFileReaderConfig is another Spring configuration which defines a bean contactReader and takes the filename from the ContactsJobParametersConfig as input.
For reading and parsing fixed length files Spring offers the FlatFileItemReader. For this reader we need to define a LineMapper which in turn needs a LineTokenizer. Since we are dealing with fixed length lines we use the FixedLengthTokenizer which takes an array of String objects for fieldnames and an array of Range objects defining the columns for a field.
The order in which the fieldnames and ranges are defined for the tokenizer need to match and the size of both arrays needs to be the same. For example, if we have a file with the following two lines containing first name and last name like:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| J | A | M | E | S | B | R | O | W | N |
| D | O | N | J | O | E |
The array of fieldnames could be something like:
new String[] { “firstName”, “lastName” }
and the array of ranges would be:
new Range[] { new Range(1, 5), new Range(6, 10) }
In the above example we see the maximum length of a line is 10 positions: positions 1 to 5 for first name and positions 6 to 10 for last name. Since we provided a range of 6-10 for last name, it is assumed that a line is 10 positions long. In case of the second line the last name has two trailing spaces. If we want this to be processed correctly we need to set the strict property on the tokenizer to false (by default this is set to true).
If we do not do this the second line cannot be processed correctly and an IncorrectLineLengthException will occur with a message “Line is shorter than max range 10”.
For the fieldnames I have created a constants class Fieldnames which has a convenience method returning an array of fieldnames, so we do not have to put this logic inside the ProcessContactsFileReaderConfig class itself. The logic for defining column ranges is also hidden from this class: I have created an enumeration ContactDetail with functional names for each column and each enumeration has a Range value. The enumeration itself has a convenience method returning an array of ranges in the correct order.
The advantage of using a FixedLengthTokenizer with ranges is that you do not have to use any substring methods for parsing a line, which can quickly become messy and incomprehensible. By defining an enumeration using clear names for each range it becomes much clearer for the reader.
For the LineMapper we provide a custom mapper class which implements the mapFieldSet method from the FieldSetMapper class taking the values from the FieldSet and mapping them to our custom model. In this case a ContactWrapper containing the original line read from the file and a Contact model containing all separate fields.
The SkipRecordCallback is used to log the first header line which needs to be skipped.
The code for the reader step is:
package nl.craftsmen.contact.job.reader;
import lombok.AllArgsConstructor;
import nl.craftsmen.contact.model.ContactWrapper;
import nl.craftsmen.contact.model.ContactDetail;
import nl.craftsmen.contact.model.Fieldnames;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.LineMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.transform.FixedLengthTokenizer;
import org.springframework.batch.item.file.transform.LineTokenizer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
@Configuration
@AllArgsConstructor
public class ProcessContactsFileReaderConfig {
private final SkipRecordCallback skipRecordCallback;
private final LineTokenizer lineTokenizer;
private final ContactsFileRowMapper contactsFileRowMapper;
@Bean
@StepScope
public ItemStreamReader<ContactWrapper> contactReader(
@Value("#{jobParameters[filename]}") final String filename) {
final var lineMapper = createLineMapper(lineTokenizer);
return createReader(lineMapper, filename);
}
private LineMapper<ContactWrapper> createLineMapper(LineTokenizer lineTokenizer) {
final var mapper = new DefaultLineMapper<ContactWrapper>();
mapper.setLineTokenizer(lineTokenizer);
mapper.setFieldSetMapper(contactsFileRowMapper);
return mapper;
}
private ItemStreamReader<ContactWrapper> createReader(LineMapper<ContactWrapper>
lineMapper, String filename) {
FlatFileItemReader<ContactWrapper> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource(filename));
reader.setLinesToSkip(1);
reader.setSkippedLinesCallback(skipRecordCallback);
reader.setLineMapper(lineMapper);
return reader;
}
}
As mentioned above it depends on a LineTokenizer:
package nl.craftsmen.contact.job.reader;
import nl.craftsmen.contact.model.ContactDetail;
import nl.craftsmen.contact.model.Fieldnames;
import org.springframework.batch.item.file.transform.FixedLengthTokenizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ContactsLineTokenizer {
@Bean
public FixedLengthTokenizer createLineTokenizer() {
final var lineTokenizer = new FixedLengthTokenizer();
lineTokenizer.setNames(Fieldnames.getFieldnames());
lineTokenizer.setColumns(ContactDetail.getColumnRanges());
lineTokenizer.setStrict(false);
return lineTokenizer;
}
}
a LineMapper :
package nl.craftsmen.contact.job.reader;
import lombok.NonNull;
import nl.craftsmen.contact.model.Contact;
import nl.craftsmen.contact.model.ContactWrapper;
import nl.craftsmen.contact.model.Fieldnames;
import nl.craftsmen.util.DateUtil;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.stereotype.Component;
import java.time.LocalDate;
@Component
public class ContactsFileRowMapper implements FieldSetMapper<ContactWrapper> {
@Override
public @NonNull ContactWrapper mapFieldSet(FieldSet fieldSet) {
return ContactWrapper.builder()
.contactRecord(fieldSet.readString(Fieldnames.CONTACT_RECORD))
.contact(Contact.builder()
.firstName(fieldSet.readString(Fieldnames.FIRST_NAME))
.lastName(fieldSet.readString(Fieldnames.LAST_NAME))
.address1(fieldSet.readString(Fieldnames.ADDRESS_1))
.address2(determineEmptyField(fieldSet.readString(Fieldnames.ADDRESS_2)))
.address3(determineEmptyField(fieldSet.readString(Fieldnames.ADDRESS_3)))
.zipcode(fieldSet.readString(Fieldnames.ZIPCODE))
.city(fieldSet.readString(Fieldnames.CITY))
.state(determineEmptyField(fieldSet.readString(Fieldnames.STATE)))
.phone(determineEmptyField(fieldSet.readString(Fieldnames.PHONE)))
.email(determineEmptyField(fieldSet.readString(Fieldnames.EMAIL)))
.iban(determineEmptyField(fieldSet.readString(Fieldnames.IBAN)))
.socialSecurityNumber(determineEmptyField(fieldSet.readString(Fieldnames.SOCIAL_SECURITY_NUMBER)))
.dateOfDeath(getDate(fieldSet.readString(Fieldnames.DATE_OF_DEATH)))
.dateOfBirth(getDate(fieldSet.readString(Fieldnames.DATE_OF_BIRTH)))
.build())
.build();
}
private String determineEmptyField(String string) {
return string.isEmpty() ? null : string;
}
private LocalDate getDate(String dateString) {
final var newDateString = determineEmptyField(dateString);
return newDateString != null ? DateUtil.parseLocalDate(newDateString, DateUtil.FORMAT_DATE_DDMMYYYY) : null;
}
}
and a SkipRecordCallback :
package nl.craftsmen.contact.job.reader;
import lombok.AllArgsConstructor;
import lombok.NonNull;
import lombok.extern.slf4j.Slf4j;
import nl.craftsmen.util.ConditionalLogger;
import org.springframework.batch.item.file.LineCallbackHandler;
import org.springframework.stereotype.Component;
@Component
@AllArgsConstructor
@Slf4j
public class SkipRecordCallback implements LineCallbackHandler {
private final ConditionalLogger logger;
@Override
public void handleLine(@NonNull String line) {
logger.info(log, "##### Skipping first header record #####: " + line);
}
}
Processing a parsed line
Now, the processing part is fairly simple. We implement the process method from the ItemProcessor class. For this use case we only need to post the Contact model to the contacts service. When an exception occurs we log the exception and the line that was read.
Earlier I mentioned the Spring Batch SkipListener which handles any exceptions in the read, write or process part. So why do we not handle the process exceptions in the @OnSkipInProcess of the StepSkipListener? This is because I am using Spring Batch Integration’s AsyncItemProcessor for processing and AsyncItemWriter for writing.
The advantage of this is that these can be configured to increase Spring Batch performance.
The downside though is that these have a side-effect when using the SkipListener because the future wrapped by the AsyncItemProcessor is only unwrapped in the AsyncItemWriter , so any exception that might occur at that time is seen as a write exception instead of a processing exception. That is why onSkipInWrite is called instead of onSkipInProcess. Therefore I have chosen to handle the exception within the ContactsProcessor itself.
The ContactsClient is just a configured WebClient to call the contacts service and post the Contact model.
package nl.craftsmen.contact.job.processor;
import lombok.AllArgsConstructor;
import lombok.NonNull;
import lombok.extern.slf4j.Slf4j;
import nl.craftsmen.contact.client.ContactsClient;
import nl.craftsmen.contact.model.ContactWrapper;
import nl.craftsmen.util.ConditionalLogger;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
@Component
@AllArgsConstructor
@Slf4j
public class ContactsProcessor implements ItemProcessor<ContactWrapper, ContactWrapper> {
private final ContactsClient contactsClient;
private final ConditionalLogger logger;
@Override
public ContactWrapper process(@NonNull ContactWrapper contactWrapper) {
try {
// Since we use Spring Batch here, we do a blocking call to the client
contactsClient.postContact(contactWrapper.getContact()).block();
} catch (Exception exception) {
logger.error(log, "Error occurred while processing contact: {}",
contactWrapper.getContactRecord(),
exception);
}
return contactWrapper;
}
}
Writing the data of a processed line
We use an ItemWriter to write the data of a processed line to some output like a database, queue or file. For my use case I do not need to write anything. Since a writer needs to be configured when using chunk based file processing, I implemented a NoOpItemWriter (no operation) which implements the write method from the ItemWriter class. This method does not do anything.
package nl.craftsmen.contact.job.writer;
import java.util.List;
import lombok.NonNull;
import nl.craftsmen.contact.model.ContactWrapper;
import org.springframework.batch.item.ItemWriter;
import org.springframework.stereotype.Component;
@Component
public class NoOpItemWriter implements ItemWriter<ContactWrapper> {
@Override
public void write(@NonNull List<? extends ContactWrapper> list) {
// no-op
}
}
So why not use a writer instead of a processor to post the Contact model to the contacts service? An AsyncItemProcessor has a ThreadPoolTaskExecutor for which you can configure corePoolSize , maxPoolSize and queueCapacity for performance tuning. More on this can be found here. An AsyncItemWriter does not have these properties. Therefore the processor part seemed more fit to use.
The AsyncItemProcessor and AsyncItemWriter
As mentioned before Spring Batch Integration’s AsyncItemProcessor and AsyncItemWriter can be configured to increase Spring Batch Performance. So what does this look like.
The AsyncItemProcessor
The AsyncContactsProcessorConfig is just another Spring configuration class. It uses a ContactsProcessor, which we already showed earlier, and a ContactsProcessorTaskExecutorConfig. The ContactsProcessor is set as the delegate on the AsyncItemProcessor and does the actual processing work. The ContactsProcessorTaskExecutorConfig is a Spring configuration class defining a bean which returns a TaskExecutor (more on this can be found here).
For the task executor we define the properties corePoolSize , maxPoolSize and queueCapacity. The values of these properties are configurable in the application.yml underprocessingcontactsjob.async.thread. Depending on your resources you can fine-tune these to your liking.
package nl.craftsmen.contact.job.processor;
import java.util.concurrent.Future;
import lombok.AllArgsConstructor;
import nl.craftsmen.contact.model.ContactWrapper;
import org.springframework.batch.integration.async.AsyncItemProcessor;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@AllArgsConstructor
public class AsyncContactsProcessorConfig {
private final ContactsProcessor contactsProcessor;
private final ContactsProcessorTaskExecutorConfig taskExecutor;
@Bean
public ItemProcessor<ContactWrapper, Future<ContactWrapper>> getAsyncProcessor() {
AsyncItemProcessor<ContactWrapper, ContactWrapper> asyncItemProcessor = new AsyncItemProcessor<>();
asyncItemProcessor.setDelegate(contactsProcessor);
asyncItemProcessor.setTaskExecutor(taskExecutor.getTaskExecutor());
return asyncItemProcessor;
}
}
package nl.craftsmen.contact.job.processor;
import java.util.concurrent.ThreadPoolExecutor;
import lombok.AllArgsConstructor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.TaskExecutor;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
/**
* Beware for deadlocks: https://www.springcloud.io/post/2022-04/spring-threadpool/#gsc.tab=0
*/
@Configuration
@AllArgsConstructor
public class ContactsProcessorTaskExecutorConfig {
private final int asyncThreadCorePoolSize;
private final int asyncThreadMaxPoolSize;
private final int asyncThreadQueueCapacity;
@Bean
public TaskExecutor getTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(asyncThreadCorePoolSize);
executor.setMaxPoolSize(asyncThreadMaxPoolSize);
executor.setQueueCapacity(asyncThreadQueueCapacity);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.setThreadNamePrefix("MultiThreadedContactProcessorTaskExecutor-");
executor.setWaitForTasksToCompleteOnShutdown(true);
executor.initialize();
return executor;
}
}
The AsyncItemWriter
The AsyncContactsWriterConfig is also a Spring configuration class. It only uses the NoOpItemWriter which is set as a delegate on the AsyncItemWriter and does the actual writing work.
package nl.craftsmen.contact.job.writer;
import java.util.concurrent.Future;
import lombok.AllArgsConstructor;
import nl.craftsmen.contact.model.ContactWrapper;
import org.springframework.batch.integration.async.AsyncItemWriter;
import org.springframework.batch.item.ItemWriter;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@AllArgsConstructor
public class AsyncContactsWriterConfig {
private final NoOpItemWriter noOpItemWriter;
@Bean
public ItemWriter<Future<ContactWrapper>> getAsyncItemWriter() {
AsyncItemWriter<ContactWrapper> asyncItemWriter = new AsyncItemWriter<>();
asyncItemWriter.setDelegate(noOpItemWriter);
return asyncItemWriter;
}
}
Conclusion
In this blog I described how I setup a Spring Batch application for processing files with fixed line length. I described the use case for which I needed this and the reason why I chose for Spring Batch. Then I highlighted the minimal Maven dependencies needed and explained some Spring Batch terminology. Then I described the different parts of the application: the job runner, job controller, job parameters and job configuration (chunk size, reader, processor, writer, skip policy and skip listener).
I showed how reading and parsing works using a FlatFileItemReader , LineMapper and FixedLengthTokenizer. I also highlighted how to use the AsyncItemProcessor and AsyncItemWriter and why you may want to use them, but I also mentioned one of the downsides using them when it comes to using the StepSkipListener.
Resources
Personal Github resources related to this blog
- Github spring-batch-demo
- Github contacts service
- Maven dependencies for spring-batch-demo
- Clean service for cleaning contacts job repository for testing purposes
- Sql file with delete statements for cleaning Spring Batch metadata tables
- Fieldnames for Contacts model
- Enumeration with functional names and ranges
External resources
- For setting up my Spring Batch application I took Ashish Singh’s javacodingskills Github and his YouTube video as a reference, but I did some refactoring on the code as described in this blog.
- Spring Batch Integration
- Spring Batch Example on CodeNotFound
- Let’s Learn Together Sessions: Spring Batch
- Increase Spring Batch Performance through Async Processing
- Configuring Skip Logic in Spring
- Spring Batch Event Listeners
- StackOverflow: Why is exception in Spring Batch AsycItemProcessor caught by SkipListener’s onSkipInWrite method?
- Spring docs ThreadPoolTaskExecutor





