In recent years, many companies have moved their software applications to the cloud. One of the most important advantages of the cloud is its scalability. Running into performance issues? Just add some more CPU, or memory, or spin up an additional instance of your application. In the cloud there is no longer the need to worry about your application’s performance, or is there? And what if you do?
As I am sure you’ll agree, cloud hosting doesn’t mean you shouldn’t worry about the performance of your application. Usability, maintainability, continuity, power usage; all are at stake. Therefore the cloud is no exception to the fact that it is always a good idea to run regular load tests.
Probably you’ve already made testing a part of your life. Now, since your applications are already there, why not run your load tests in the cloud too?
Enter the swarm
One of the biggest advantages of distributed load testing, is that you are not limited to one single server. With the aptly named load tester Locust you can easily scale up the load generator to simulate any load imaginable. Let’s explore what Locust offers and how you can get it airborne to run a distributed load test on Kubernetes.
Configuring your Locust test
Locust is a performance testing tool written in Python. Its user test scenarios are also written in plain-old Python. These scripts are incredibly easy for developers to work with, because they contain no callbacks or any other kind of asynchronous mechanisms.
The reason we don’t need any asynchronous mechanisms is because Locust itself is single-threaded. A setup of Locust consists of one master process and any number of worker processes. You simply up the number of worker processes, if you need to simulate more users accessing your application simultaneously.
See for example this test scenario.
import time
from locust import HttpUser, task, between
class ExampleUser(HttpUser):
wait_time = between(1, 2.5)
@task
def homepage(self):
self.client.get("/main")
@task(3)
def browse_articles(self):
for article_id in range(10):
self.client.get(f"/article?id={item_id}", name="/article")
time.sleep(1)
def on_start(self):
self.client.post("/login", json={"username":"locust", "password":"locust"})
What we’ve defined here is user behaviour. When we run our load test, we can configure how many users we want to simulate and at what speed new users should spawn. Each user will first execute the on_start method, and then keep executing the methods annotated with @task indefinitely, until the load test is terminated.
The tasks are picked at random, but you can assign a weight to them to make sure some tasks are picked more often than others. In this example, the homepage task has a weight of 1 and the browse_articles task has a weight of 3, so each worker is 3 times more likely to pick browse_articles than homepage.
Because we’ve defined our user to be a HttpUser, we are able to use self.client in order to execute HTTP requests in our tasks. As you can see in the body of the browse_articles task, you can perform multiple requests per task.
It’s also possible to capture the response code or the response body and use that to determine the next action to be executed. After completing a task, each user will wait a moment before picking up a new task. You can configure this to be a constant waiting time, but in this example, we’ve added some randomness by making the users wait between 1 and 2.5 seconds.
Running your test on Kubernetes
Next up, it’s time to deploy our test scenario to the cloud. If you search the internet for a guide on this, you might find this tutorial for the Google Kubernetes Engine. The tutorial is based on an outdated version of Locust. Fortunately, it instructs you on how to build the docker image, so the only thing left is to update the image yourself.
Just find the file docker-image/locust-tasks/requirements.txt and update each dependency to the latest version. You can check what versions are the latest versions on the Python Package Index. Note that the locustio dependency should be changed to locust and the msgpack-python dependency can be removed after updating msgpack. Next, find the run.sh file in that same directory, change –slave to –worker and change $LOCUST_MASTER to $LOCUST_MASTER_NODE_HOST.
The last of these two changes are needed because of the updated version of Locust. The tasks.py file won’t work with the newest version of Locust neither, so replace it with your own test scenario.
Almost ready for lift-off
Take a look at the files in the kubernetes-config directory. For this part, please refer to the tutorial for the Google Kubernetes Engine. It perfectly explains the purpose of these files and how they are used to deploy your Locust test to the cloud. Please note that in the locust-worker-controller.yaml file, you’ll need to change LOCUST_MASTER to LOCUST_MASTER_NODE_HOST, just like you did for the run.sh file.
If you followed all the steps in the tutorial, you should now be able to access the Locust web interface, which looks like this:
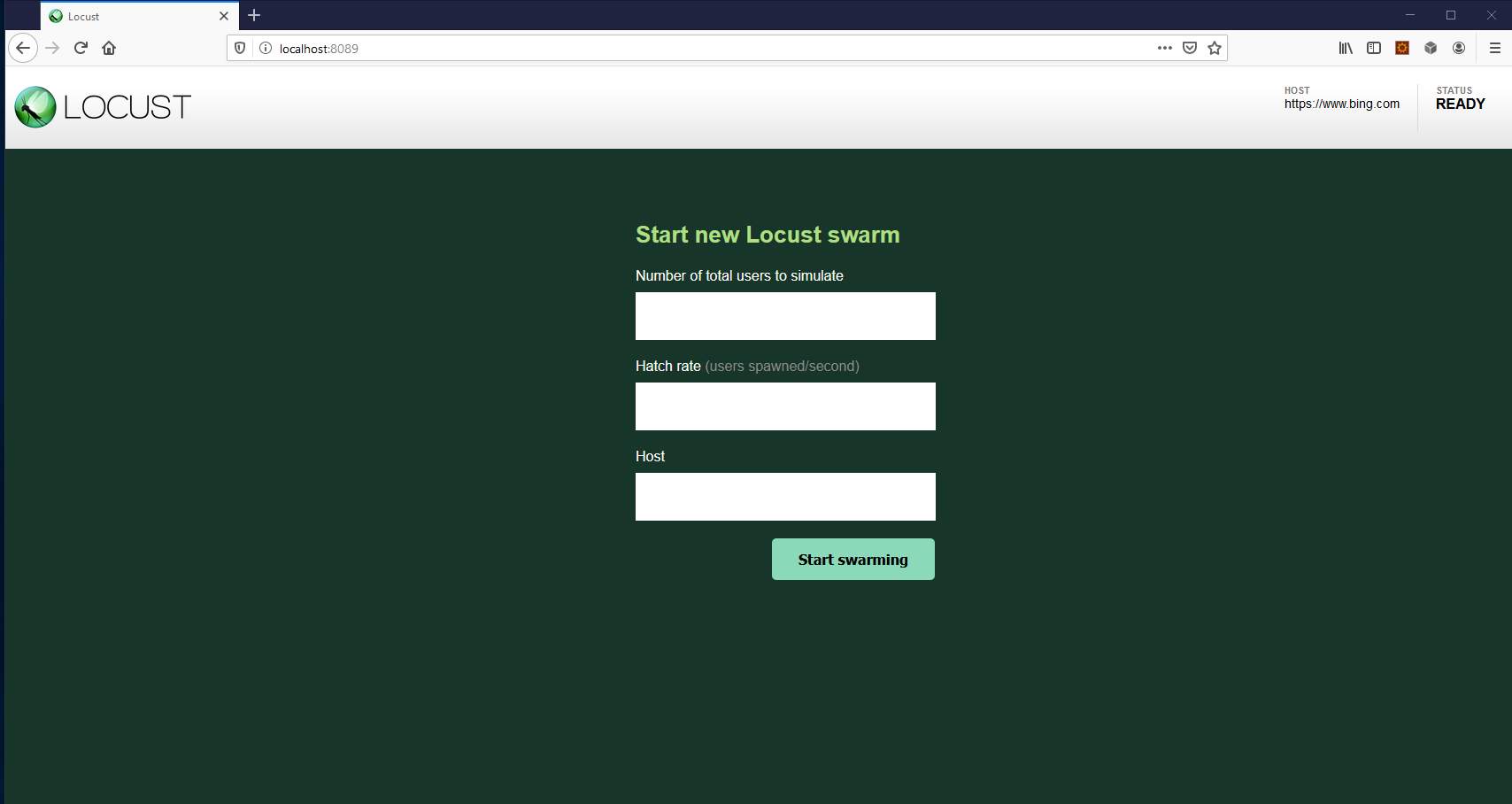
This is where you configure the number of users simulated in your load test and the speed at which new users spawn. You should also think about how many Locust workers you would like to run simultaneously (configure that in Kubernetes).
For example, run the command kubectl scale deployment/locust-worker –replicas=5 to run 5 workers simultaneously. Locust will automatically gather metrics during the load test. You can view those on the web interface while the test is running and download an overview after it’s finished.
Using a Helm chart
If you don’t want to build your own docker image, the Locust documentation suggests using a Helm chart. Find the currently most up to date Helm chart here. The chart will take care of most of the setup for you. Including creating configmaps for storing the Locust files in Kubernetes, so there is no need to build custom docker images.
Even though Helm charts are not maintained or supported directly by Locust maintainers, in this simple setup there really is no disadvantage to using one. So be sure to give it a try, and see if your application holds up to the insatiable appetite of Locust!





